过滤向量搜索:RAG 系统中的关键技术
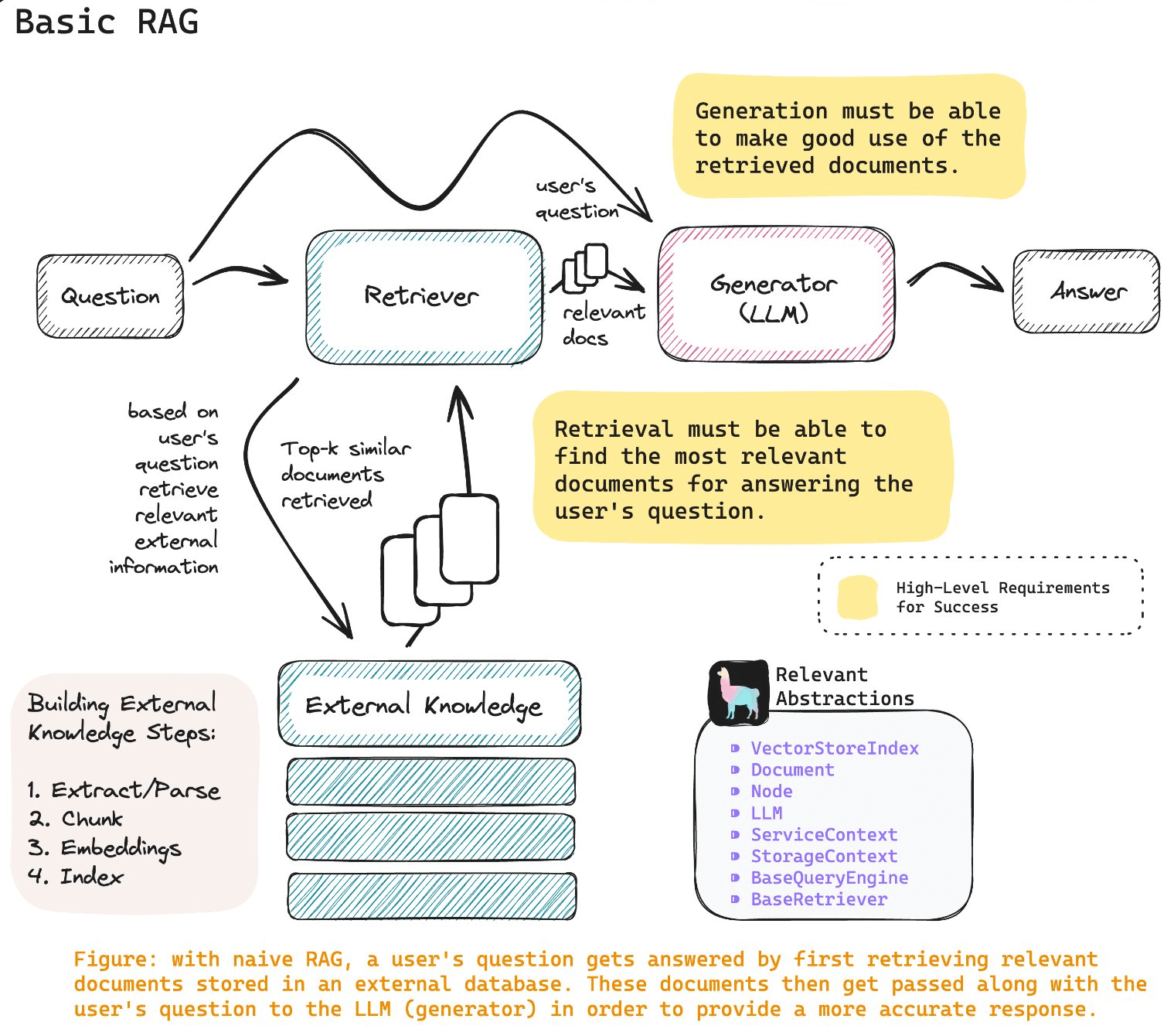
在基本的 RAG (Retrieval-Augmented Generation) 系统中,文档(包括文本、PDF、Word、PPT 等)首先经过切割 (chunking) 处理,提取出嵌入向量 (embedding) 后存储于向量数据库中进行索引。用户提问时,系统先从索引中检索与用户问题最相关的文档,然后将用户问题和相关文档片段送给大型语言模型 (LLMs) 生成更准确的答案。
 来源:@jerryjliu0
来源:@jerryjliu0
- RAG 显著改善了 GenAI 应用的结果;
- 即使向量数据库中的数据是 GPT-4 训练时已知的,使用 RAG 的 GPT-4 也优于不使用 RAG 的版本;
- 一些开源的小型模型,在采用 RAG 后,其效果能接近使用 RAG 的 GPT-4。
RAG 系统的核心是存储了大量文档的向量数据库。这个数据库能否快速准确地搜索到与问题相关的文档,对 RAG 系统的效果至关重要。向量数据库所需关注的不仅是向量数据,还包括与向量相对应的元数据。充分利用这些元数据进行过滤搜索,可以显著提高搜索的准确度和整个 RAG 系统的效果,进而改善 GenAI 应用的体验。
例如,假设向量数据库中存储了大量的论文,用户可能只关心特定学科或作者。因此,在搜索时加入相应的过滤条件可以显著提高搜索结果的相关性。另外,带过滤的向量搜索还可用于多租户场景,例如聊天或 ChatPDF 类应用中,用户只需搜索自己的聊天记录或文档。此时,如果将每个用户作为数据库中的一个分区 (partition),会给数据库本身增加很大负担,并且对查询性能产生负面影响。因此,使用用户 ID 作为过滤条件进行带过滤的向量搜索是一种更自然的操作方式。
前过滤 vs. 后过滤
在实现带过滤的向量搜索时,存在前过滤和后过滤两种方式。前过滤 (pre-filtering) 先通过元数据筛选出符合条件的向量,再在这些向量中进行搜索。这种方法的优点是,如果用户需要 k 个最相似的文档,数据库能够保证返回 k 个结果。后过滤 (post-filtering) 则是先进行向量搜索,得到 m 个结果,再对这些结果应用元数据过滤。这种方式的缺点是,由于不确定 m 个结果中有多少符合元数据过滤条件,最终结果可能不足 k 个,特别是当符合过滤条件的向量在整个数据集中数量较少时。
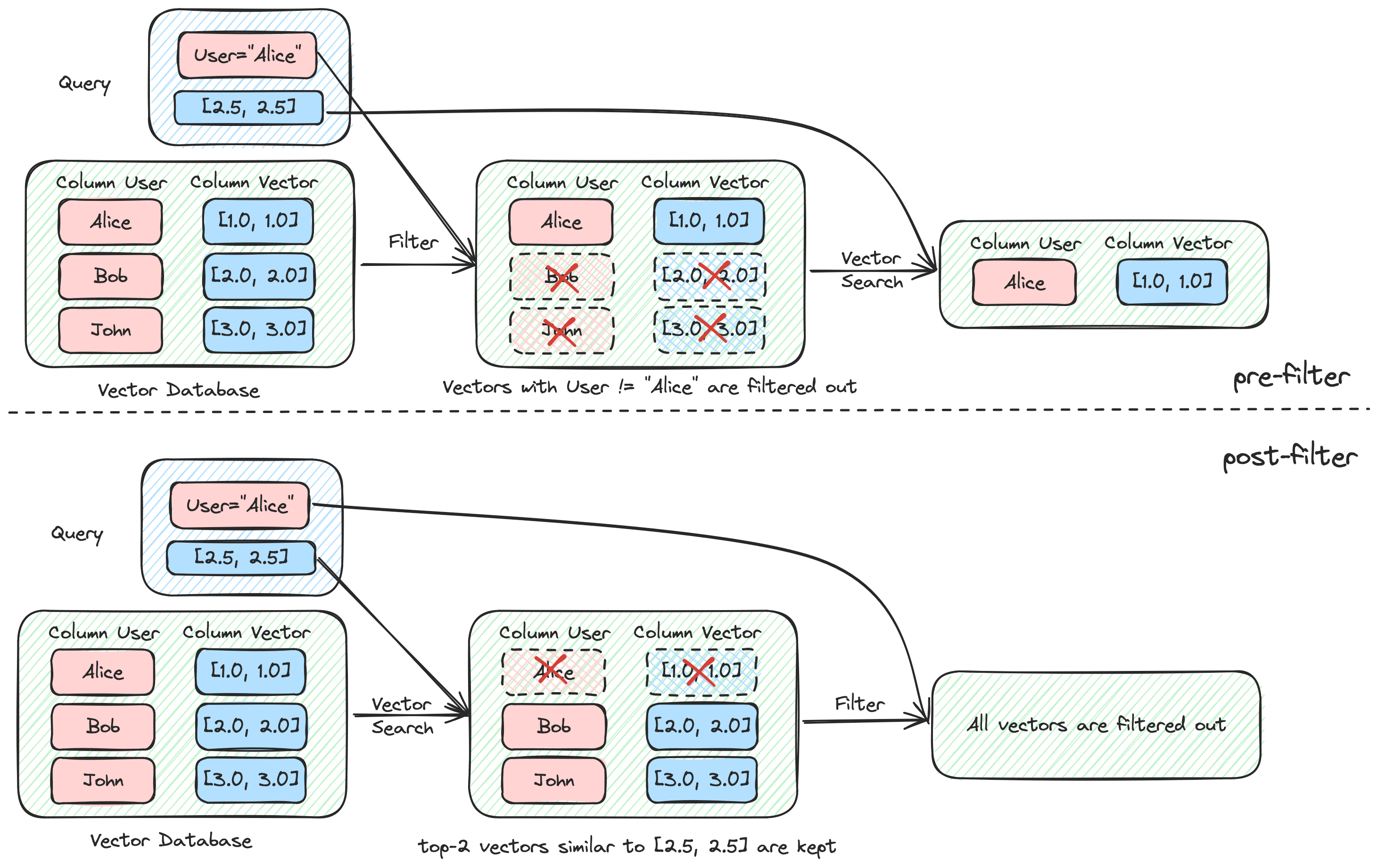
前过滤的挑战在于如何高效地进行元数据过滤,以及在过滤后向量数量较少时,向量索引的搜索效率。例如,使用广泛的 HNSW (Hierarchical Navigable Small World) 算法在过滤比例较低(例如过滤后只剩下 1% 的向量)时,搜索效果会大幅下降。为此,Qdrant 和 Weaviate 进行了一些探索,通常的做法是在过滤比例较低时,从 HNSW 算法回退到暴力搜索。
Benchmark 结果
参考对多个向量数据库的云服务进行了测试的 MyScale Vector Database Benchmark。在过滤比例为 1% 的测试中(即施加过滤条件后,全库中只有 1% 的向量满足条件),结果如下:
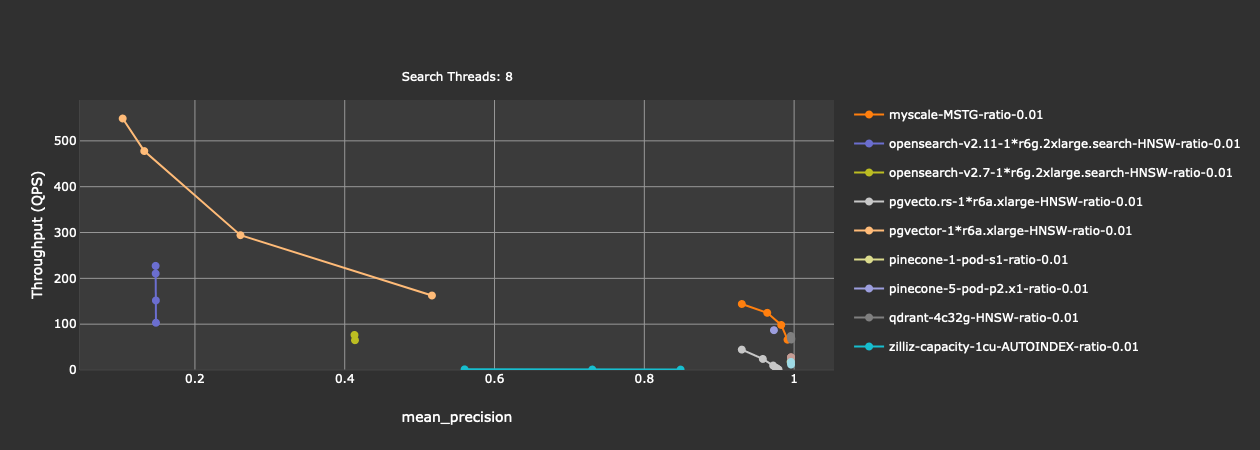
从结果来看,OpenSearch(两个版本 v2.7 和 v2.11)和 pgvector 的精度过低,不足 50%。Zilliz 的 capacity 模式性能过低,不到 1 QPS (query per second)。排除这些选项后,再看一下剩下的结果:
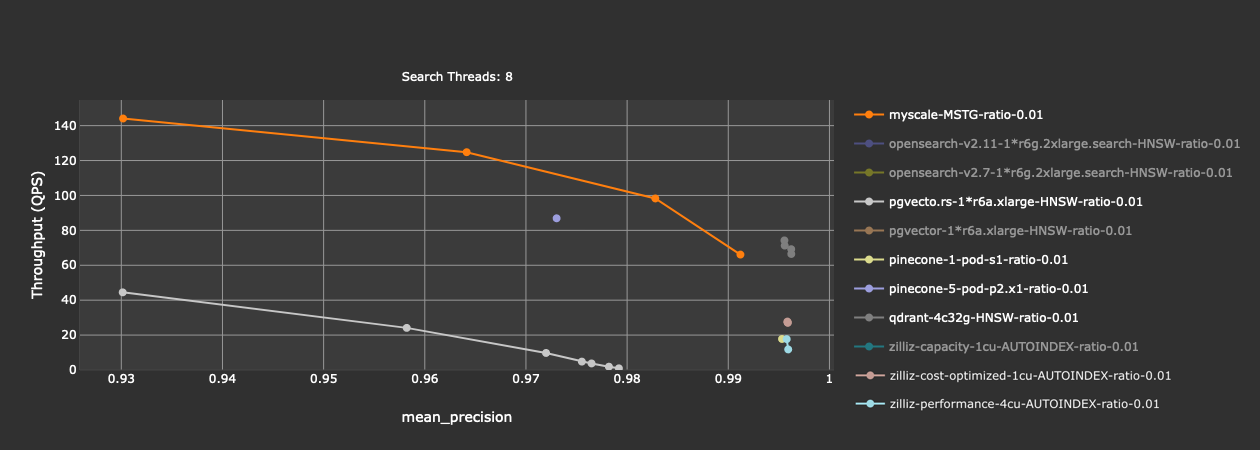
可以看出,精度和性能都比较好的数据库包括 MyScale、Qdrant 和 Pinecone (p2 pod)。而 Pgvecto.rs、Zilliz (Performance & Cost-optimized 模式)、Pinecone (s1 pod) 的精度还不错,但性能较低。在这些数据库中,MyScale 和 Pinecone 只提供全托管的 SaaS 服务。Qdrant 和 Zilliz (开源版本为 Milvus) 既有 SaaS 服务也有开源版本。Pgvecto.rs 目前是一款完全开源的 Postgres 插件,暂无 SaaS 版本。
总结
RAG 系统结合了大型语言模型和向量数据库,通过处理用户问题和相关文档片段,显著提升了 GenAI 应用的效果。向量数据库的搜索效率和准确度是系统性能的关键。优化搜索策略(如前过滤和后过滤)和选择合适的向量数据库是提升 RAG 系统效果的重要因素。通过对各种数据库的综合评测,用户可以为不同需求选择最佳解决方案,推动 GenAI 领域的进步。